Chapter 7: The t-distribution, confidence intervals, and t-tests
Author
Jakub Těšitel
The t-distribution
For any fixed value X, a t-value can be computed from a sample of a quantitative random variable using this formula: \[
t = \frac{X - \overline{x}}{s_{\overline{x}}}
\] where \(\overline{x}\) is the sample mean and \(s_\overline{x}\) is its associated standard error. Recall here, that \(\overline{x}\) is the estimate of the population mean and \(s_{\overline{x}}\) quantifies its accuracy. As a result, the t-valuerepresents the estimate of the difference between\(X\)and the population mean.
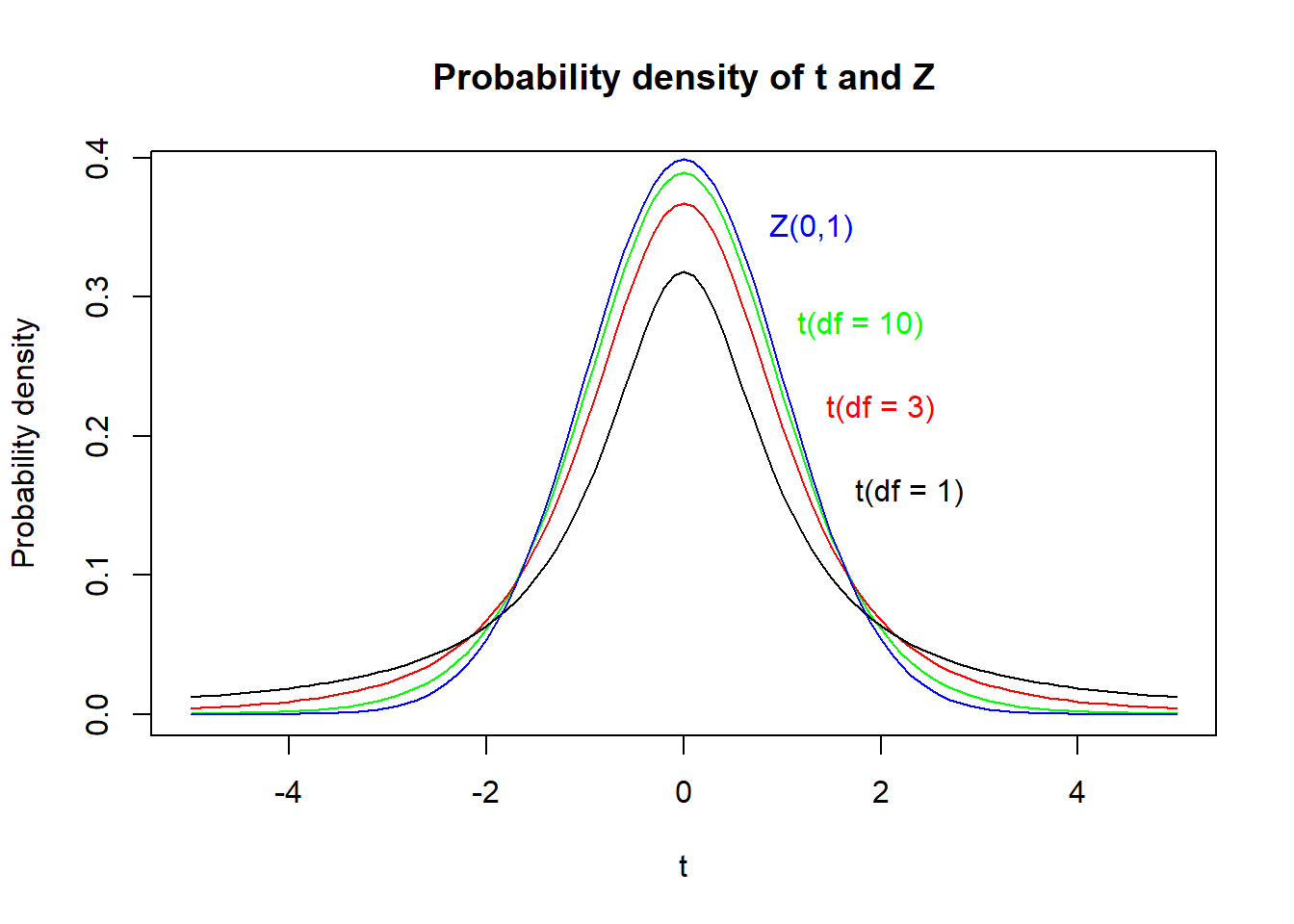
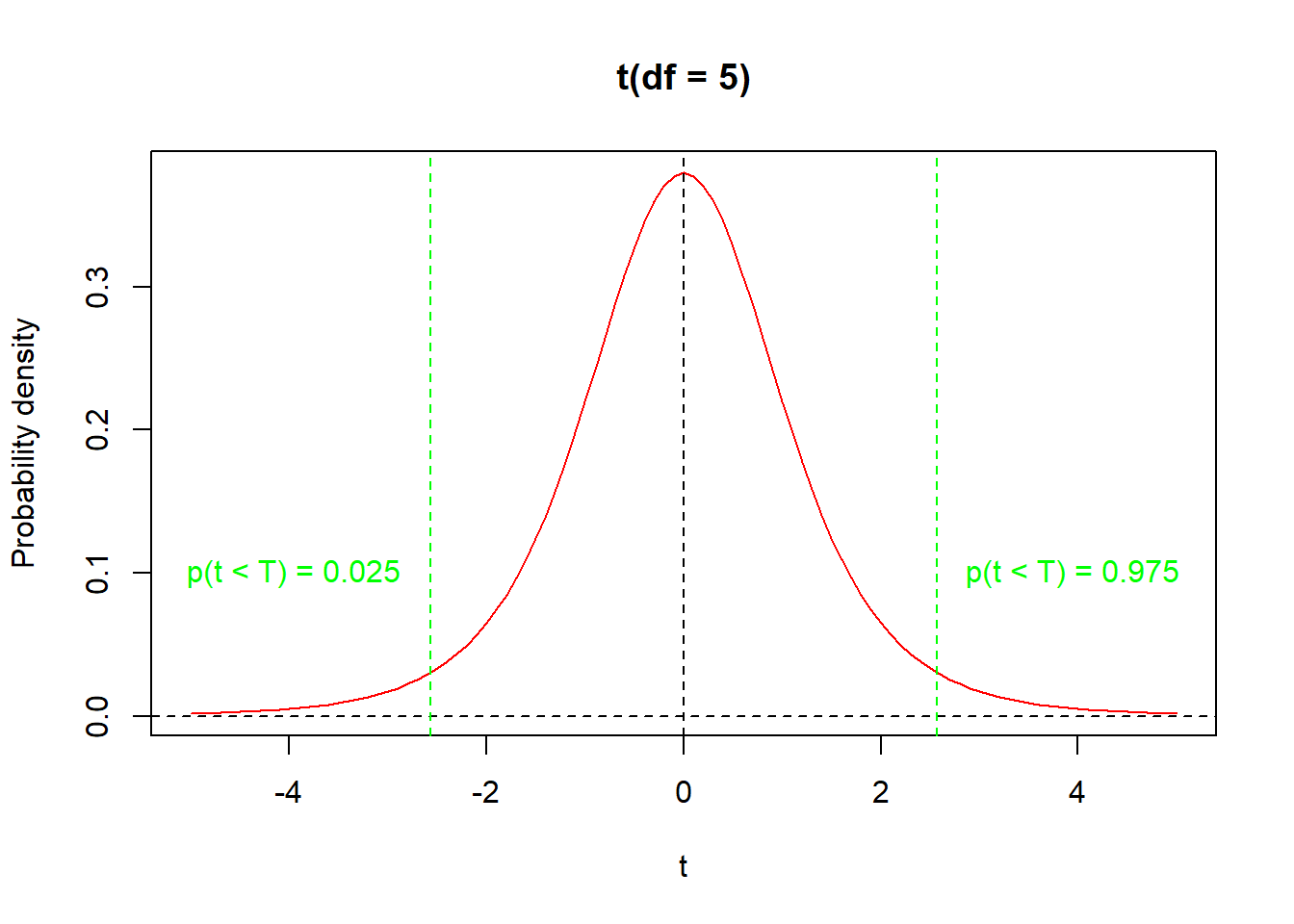
Because \(\overline{x}\) is a random variable, t-value is also a random variable and its probability distribution is called the t-distribution. Its shape is closely similar to \(Z\) (standard normal distribution with \(\mu = 0\) and \(\sigma^2 = 1\)). In contrast to \(Z\), the t-distribution has a single parameter – the number of degrees of freedom, which equals the \(number\ of\ observations\ in\ a\ sample - 1\). In fact, \(t\) approaches \(Z\) asymptotically for high DF (Figure 1). Similarly to the normal distribution, the t-distribution is symmetric, and its two tails must be considered when computing probabilities (Figure 2).
Show R Script
# t(df = 10)curve(dt(x, df =10), col ='green', xlim =c(-5, 5), xlab ='t', ylab ='Probability density',main ='Probability density of t and Z')text(x =1.8, y =0.28, label ='t(df = 10)', col ='green')# t(df = 3)curve(dt(x, df =3), add = T, col ='red')text(x =2, y =0.22, label ='t(df = 3)', col ='red')# t(df = 1)curve(dt(x, df =1), add = T, col ='black')text(x =2.3, y =0.16, label ='t(df = 1)', col ='black')# Z(mu = 0, sd = 1)curve(dnorm(x, mean =0, sd =1), col ='blue', add = T)text(x =1.3, y =0.35, label ='Z(0,1)', col ='blue')
Figure 1: Probability density plot of t-distributions with different DF and their comparison to standard normal distribution (Z). Notice how t-distribution approaches Z distribution with increasing df.
Show R Script
# curve for t(df = 5)curve(dt(x, df =5), xlim =c(-5, 5), col ='red',xlab ='t', ylab ='Probability density', main ='t(df = 5)')# zeroabline(h =0, lty =2)# maximum probability lineabline(v =0, lty =2)# 2.5% quantileabline(v =qt(p =0.025, df =5), lty =2, col ='green')# 97.5% quantileabline(v =qt(p =0.975, df =5), lty =2, col ='green')# text labelstext(x =-3.95, y =0.1, labels ='p(t < T) = 0.025', col ='green')text(x =3.95, y =0.1, labels ='p(t < T) = 0.975', col ='green')
Figure 2: The t-distribution with its two tails and the 2.5% and 97.5% quantiles.
Confidence intervals for the mean value
The t-distribution can be used to compute confidence intervals (CI), i.e. intervals within which the population mean value lies with a certain probability (usually 95%). The confidence limits (CL) within which the CI lies are determined using these formulae: \[
CL_{low} = \overline{x} - t_{(df,\ p = 0.025)}s_{\overline{x}}
\]
\[
CL_{high} = \overline{x} + t_{(df,\ p = 0.025)}s_{\overline{x}}
\]
where \(t(df,\ p)\) equals 2.5% or 97.5% probability quantile of t-distribution with given df and \(s_{\overline{x}}\) is the standard error of the sample mean. These intervals can be used as error bars in barplots or dotcharts. In fact, they represent the best option to be used like this (in contrast to standard error or 2*standard error).
Single sample t-test
Confidence intervals can also be used to determine whether the population mean differs significantly from a given value: a value lying outside the CI is significantly different (at 5%-level of significance) while a value lying inside is not. This is closely associated with the single sample t-test, which tests a null hypothesis that a value \(X\) equals the population mean. Using the formula for t-value and DF, the t-test determines the probability of Type I Error associated with rejection of such a hypothesis.
Student t-test
If means can be compared with an a priori given value (by the single sample t-test), two means of different samples should also be comparable. This is done by a two-sample t-test1, which quantifies uncertainty about the values of both means considered:
\[
t = \frac{\overline{x}_1 - \overline{x}_2}{s_{\overline{x}_1 - \overline{x}_2}}
\]
where \(\overline{x}_1\) and \(\overline{x}_2\) are arithmetic means of the two samples and \(s_{\overline{x}_1 - \overline{x}_2}\) is the standard error of their difference.
The \(s_{\overline{x}_1 - \overline{x}_2}\) is computed using the following formula:
where \(s_p^2\) is the pooled variance2 of the two samples, and \(n_1\) and \(n_2\) are sample sizes. Pooling variance like this is only possible if the two variances are equal. Correspondingly, the equality of population variances, called homogeneity of variance, is one of the t-test assumptions. In addition, the t-test assumes that the samples come from populations that are distributed normally. There is also the universal assumption that individual observations are independent.
The t-test is relatively robust to violations of the assumptions about the homogeneity of variance and normality (i.e. their moderate violation does not produce strongly biased test outcomes). If variances are not equal, Welch approximation of t-test (Welch t-test) can be used instead of the original Student t-test. A slightly modified formula is used for the t-value computation, and also the degrees of freedom are approximated (as a result, df is usually not an integer). Note here that the Welch t-test is used by default in R. In the original (two-sample) Student t-test, the DF is determined as: \[
DF = n_1 - 1 + n_2 - 1
\] where \(n_1\) is the size of sample 1 and \(n_2\) is the size of sample 2.
Paired t-test
Paired t-test is used to analysis of data composed of paired observations. For instance, a difference in length between left and right arms of people would be analyzed using a paired t-test. The null hypothesis, in this case, is that the difference within the pair is zero. In fact, a paired t-test is fully equivalent to a single sample t-test comparing the within-pair difference distribution with zero. The number of degrees of freedom is determined as DF = n – 1 because there is just one sample (of paired values) in a paired t-test.
NoteHow to do in R
1. t-distribution computations
As in case of normal distribution, where we used dnorm() and qnorm(), similar functions are available also for the t-distribution: dt(), qt() and others. For instance,
qt(p =0.025, df =5) # or any other df
can be used to compute the difference between the lower confidence limit and the mean.
2. t-test
Function t.test(). For two samples, the best way is to use a classifying factor and response variable in two columns. Then,
t.test(response ~ factor)
can be used. But,
t.test(sample1, sample2)
is also okay and will work.
Important parameters
var.equal - switches between Welch and Student variants. Defaults to FALSE (Welch)
mu - a priori null value of the difference (relevant mainly for a single sample test)
paired - when TRUE, it specifies a paired t-test
Exercises
Import the data people used in the first practicals. Plot a dotchart displaying height means with 95% confidence intervals for each of the groups of people defined by sex and eye color.
Import the lettuce data again, used in the graph plotting workshops. Test whether green- and red-leaved lettuce varieties differ in harvest mass and harvest date. Check the patterns on the corresponding plots.
Five blocks were divided into two plots, one of which was fertilised and the other not. The experiment looked like this in the field:
Figure 1: Randomized block design. Picture generated by ChatGPT-4.
The resulting plant biomass was as follows:
Table 1: Plant biomass by different treatment.
Block
1
2
3
4
5
fertilized
23
25
36
19
22
non-fertilized
20
24
33
18
21
Does fertiliser application affect biomass production?
#AI Ask your favourite LLM to solve any of the tasks 1-3 and generate the corresponding R script.
Tasks for independent work
10 rats were fed nutrition enriched in magnesium since their birth. Ten additional control rats were fed the same nutrition, except that no extra magnesium was added. The results of erythrocyte counting in the blood of each of the rats are listed in the data frame below. Does Mg affect the number of erythrocytes?
Heights of siblings (brother and sister) were measured at their adult age in eight families. The results (height in cm) are summarized in the table below. Is there any significant difference in height between siblings of different sex?
Days with snow cover per year were monitored in Brno in 15 successive years. The resulting numbers were as following. Is the mean number of days with snow cover significantly different from 58 days predicted for Brno on the basis of a global climatic model?
Wine was cultivated on 8 wine-yards in the Niederösterreich region. Red grape varieties Cabernet Sauvignon and Zweigeltrebe were cultivated on each of the wine-yards. Grapes were harvested on the same date, pressed and glucose content in the resulting juice was measured. The results are summarized in the table below. Do the two wine varieties significantly differ in mean glucose content? (Glucose content was measured in kg/hl)
Speed of swimming of two frog species was measured by a behavioral biologist. Following data were obtained. Do the two species significantly differ in speed of swimming? (Speed was measured in cm/s)
A farmer tested the yield difference between two varieties of rye. He cultivated each of them on six fields and measured the grain yield (in tonnes per hectare). The following numbers were obtained. Does yield differ between the two varieties? (Yield was measured in t/ha)
Called also Student t-test after its inventor William Sealy Gosset (1976-1937), who used the pen name Student.↩︎
Pooled variance is basically the weighted average two or more group variances. The formula looks like this: \(s_p^2 = \frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 - 2}\)↩︎